Do You Know Chris Flowers?
Building a Deep Learning Convolutional Neural Network for American Sign Language(ASL)
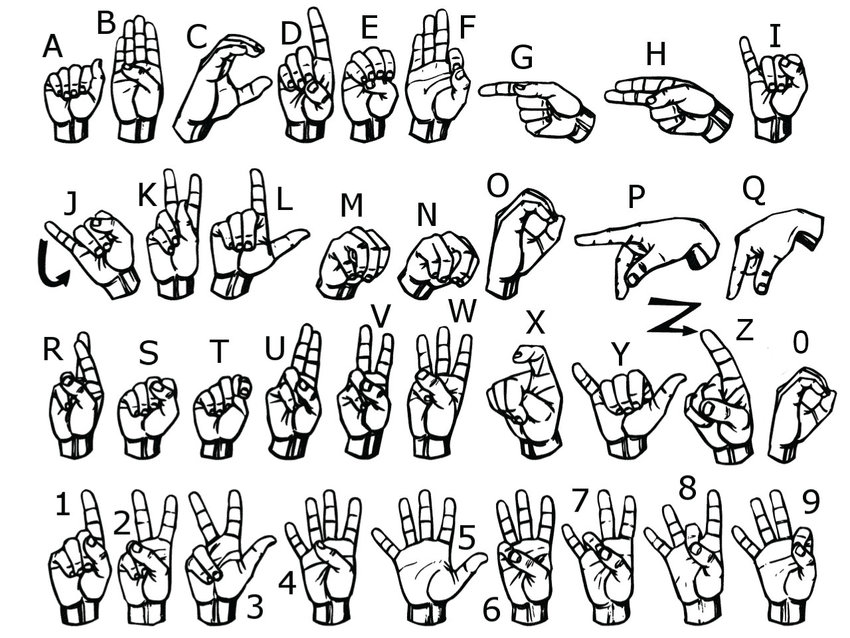


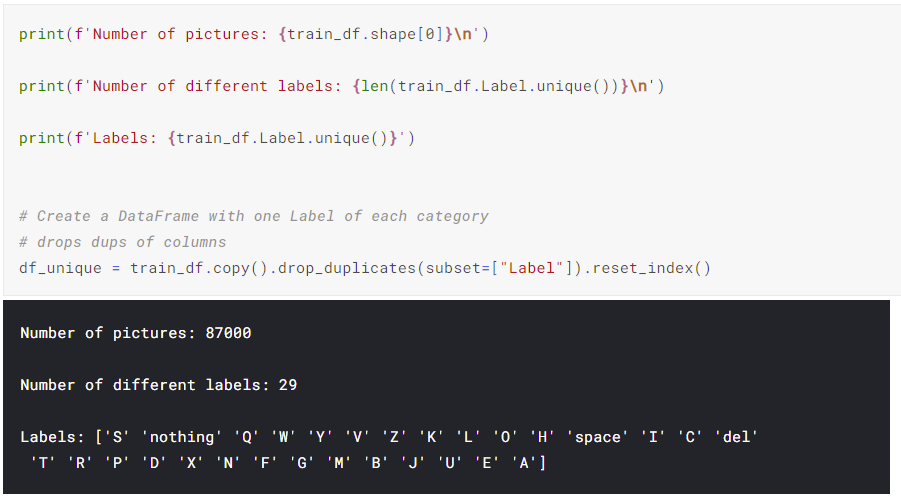
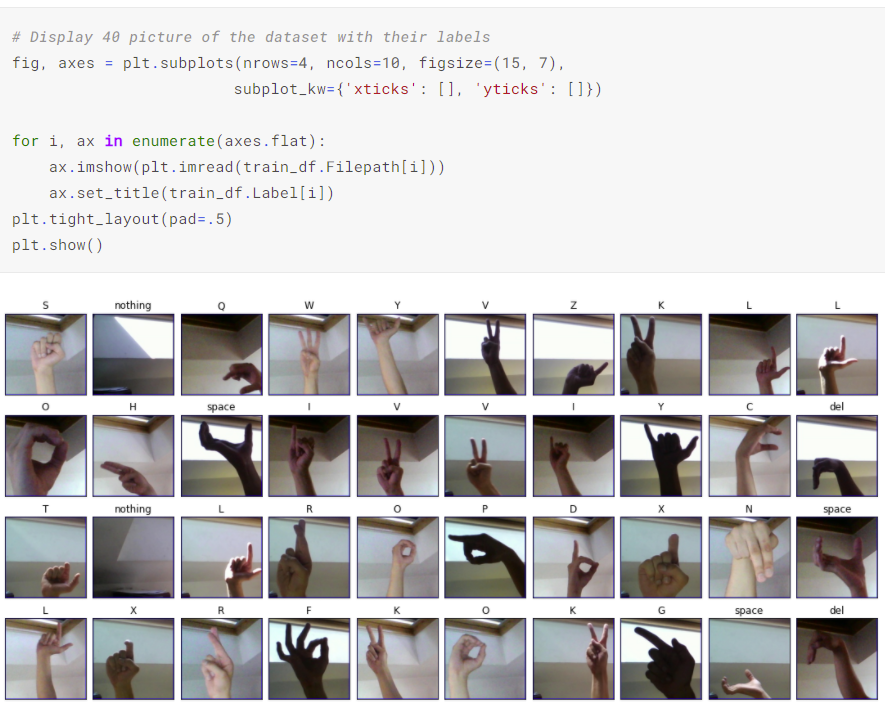
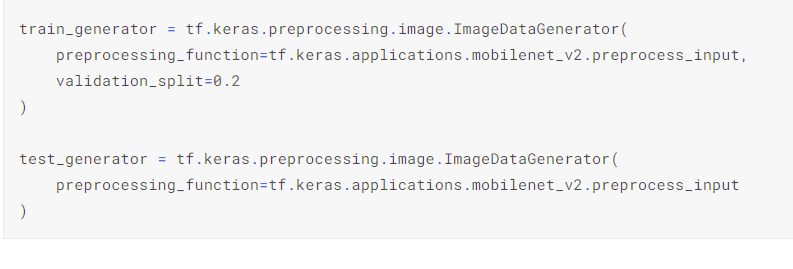
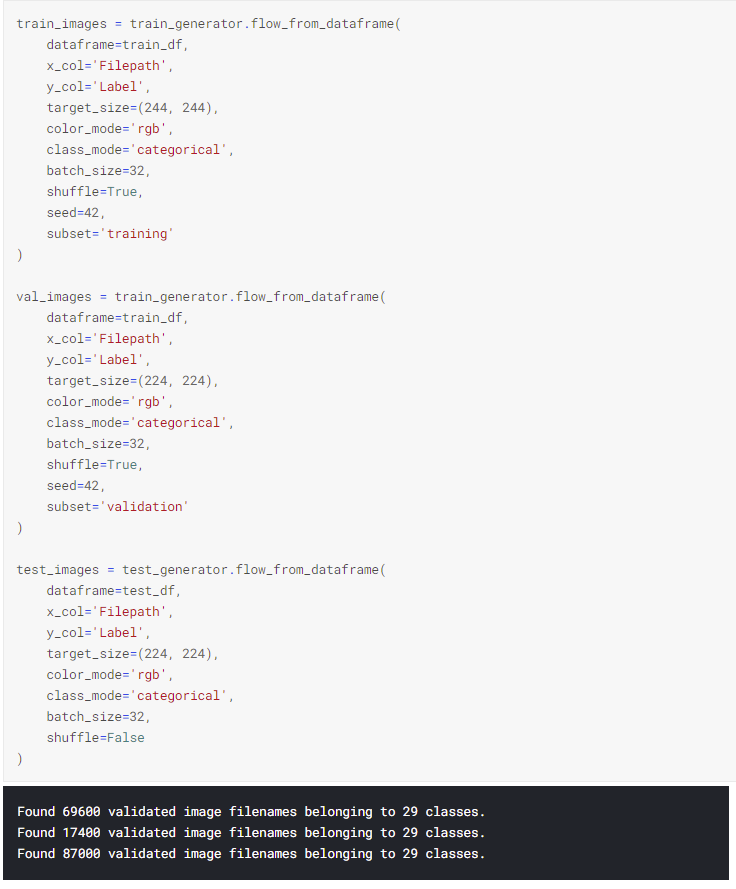

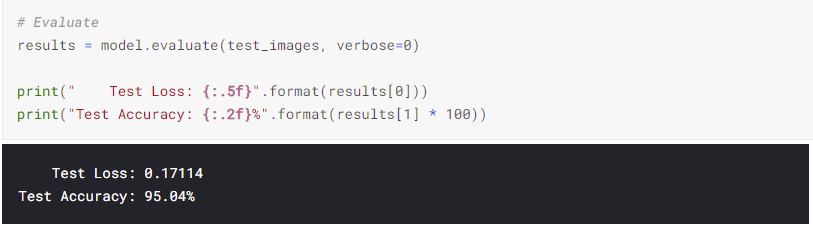

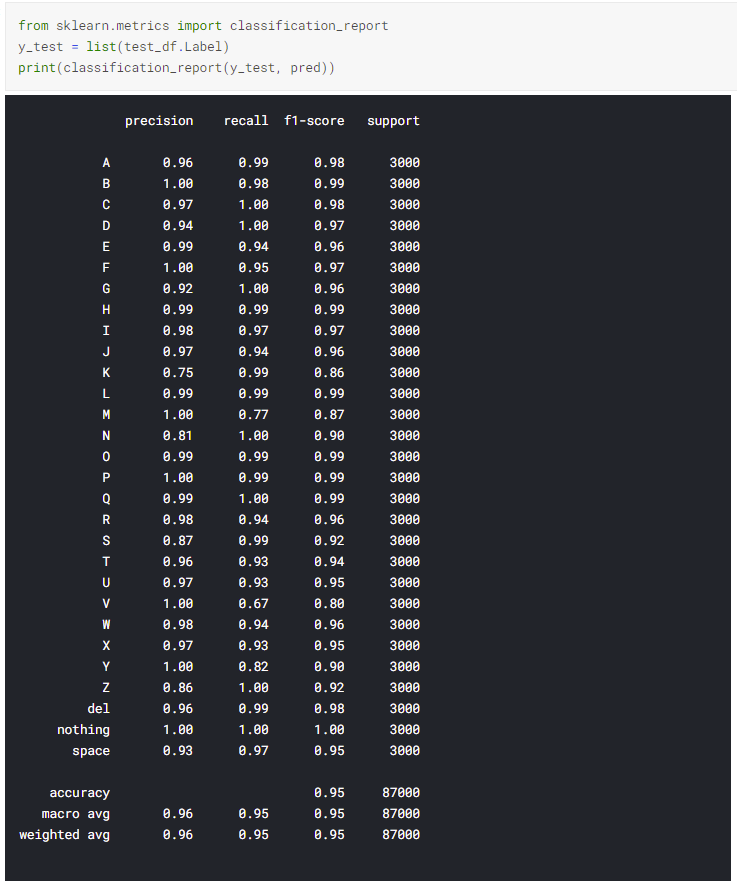
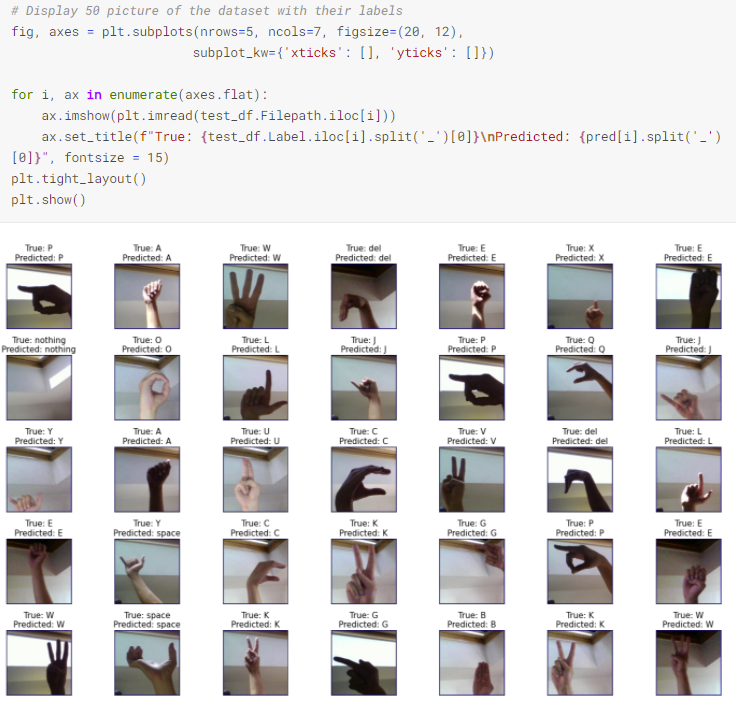
Building a Deep Learning Convolutional Neural Network for American Sign Language(ASL)